What kind of mobility data are we analyzing?
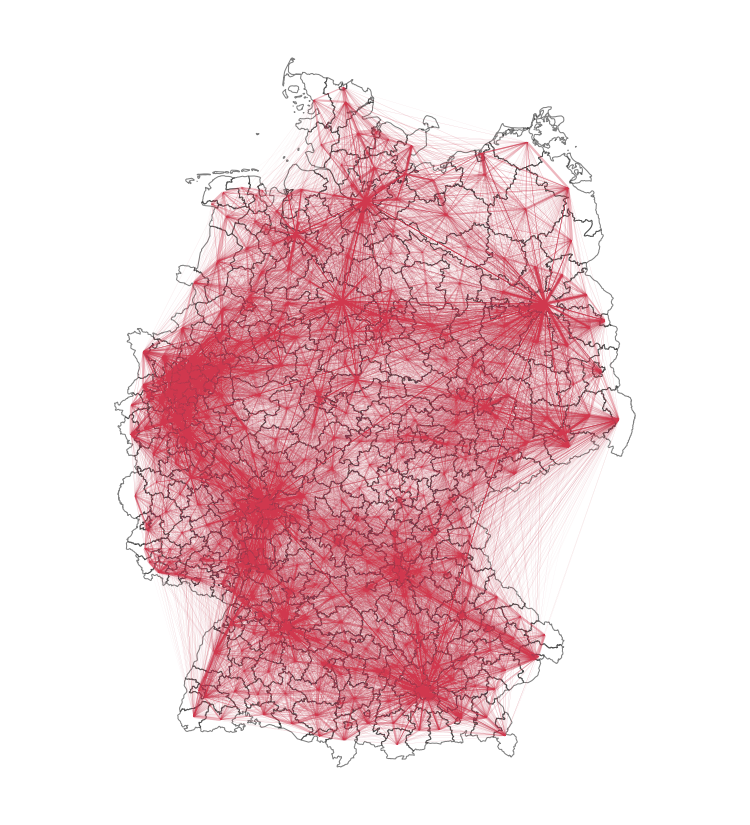
We’re analyzing mobility flows in Germany, which are gathered from mobile phone data. Our data contains the trips that take place between areas. These areas are on the level of counties in Germany (Landkreise).
The data only contains the number of trips within and between areas. Deducing the movement of a single individual from this is not possible.
A trip can start and end in the same area, but we don’t know where within the area it took place. All movements in an given timeframe are then summed up, for example daily.
It is not possible to identify single individuals from these aggregated numbers. The data also does not contain any personal information such as age or gender.
Where is the data from?
Mobility flows of this kind are collected by many mobile phone providers. We use data from the german Telekom, which is distributed by the company T-Systems, as well as data from Telefónica, which is analyzed and aggregated by the company Teralytics. This kind of data is commercially available and is used, for example, by public transportation companies, for predicting traffic or to improve road infrastructure.
Here’s how the data is generated: The mobile phone provider registers which devices are connected to certain cell towers. This raw data is then being aggregated to mobility flows. All personal information is stripped from the spatial information at this point. Preserving anonimity is the primary goal in this process. T-Systems developed its anonymization procedure in collaboration with the Federal Commissioner for Data Protection and Freedom of Information (BfDI. At Telefónica, the basis for providing this information is the data anonymization platform DAP, which was developed in collaboration with the BfDI (see further information on anonymization at Telefónica).
What is a movement?
A movement is registered by the mobile phone provider when an individual switches cell tower areas, and ends when the person becomes stationary again. The start- and end-tower can be the same.
The movement is then attributed to the corresponding spatial aggregation area, for example the county (Landkreis), and added to all other movements counted in a time frame. If the total number of movements between two areas fall below a certain threshold, the movements are not included in the data to ensure the anonymity of individuals.
How do we compute the change in mobility?
In our analysis and the dashboard, we show the deviation in mobility from a “normal” baseline. For this, we count all movements and compare them to the number we would expect in a usual, comparable timeframe.
As a comparable timeframe for March 2020 we use the number of movements in an averaged week from March 2019. When comparing single days, we always compare it to the corresponding weekday from the averaged week. Update: The live mobility monitor and the current plots now compares the mobility of the current month from 2019, not necessarily March 2019. More details can be found here.
Mathematically speaking: If we assume that \(N_i^{(t)}\) is the number of movements in an area \(i\) in a timeframe \(t\), and \(t^*\) is a comparable timeframe with normal mobility, the change in mobility \(\Delta n\) can be calculated as:
\[\Delta n=(N_i^{(t)} / N_i^{(t^*)})-1\]