Analyse zur Stichprobenverzerrung in Kontakt-Daten
Bei der Erhebung von Daten kann es schnell dazu kommen, dass bestimmte Gruppen der Bevölkerung überrepräsentiert sind, die Bevölkerungsstichprobe ist sozusagen verzerrt. Ein bekanntes Beispiel für diese Stichprobenverzerrung kommt aus der medizinischen Forschung, wo in klinischen Studien neue Medikamente überproportional häufig an Männern getestet werden. Eine Konsequenz ist, dass eine vermeintlich sichere Dosierung von Medikamenten dann gerade bei Frauen unvorhergesehene Nebenwirkungen auslösen kann.
Nun stellt sich die Frage, ob die Gruppe der Nutzer:innen, deren Kontakte erfasst werden (siehe Methodik), die gesamte Bevölkerung fair repräsentieren. Die Stichprobe ist mit knapp einem Prozent der Bevölkerung zwar sehr groß im Vergleich zu anderen Studien, aber sie ist bei weitem zu klein, um eine Verzerrung allein der Anzahl wegen auszuschließen.
Unterschiede in Nutzerzahlen zwischen Ländern als Indiz
Da die Daten voll anonymisiert sind (wir erhalten lediglich den Mittelwert und die Standardabweichung der täglichen Kontakte), scheint es auf den ersten Blick schwer eine Verzerrung festzustellen. Jedoch kennen wir zusätzlich noch die Anzahl der Nutzer:innen in den einzelnen Bundesländern. Somit könnten wir z.B. sagen, wenn Bundesländer mit einem besonders hohen Durchschnittsalter besonders viele Nutzer:innen haben, dass die Stichprobe junge Bevölkerungsschichten unterrepräsentiert.
In der unteren Grafik erkennt man, dass die Nutzer:innen in Sachsen-Anhalt und Mecklenburg-Vorpommern den größten Anteil der Bevölkerung repräsentieren (etwa 0.9%) verglichen mit den anderen Ländern. Hingegen werden in Berlin und Hamburg etwa 0.3 % der Bevölkerung erfasst. Also scheinen Regionen mit hoher Bevölkerungsdichte einen geringen Anteil an Nutzer:innen zu haben. Außerdem deutet sich ein Nord-Süd Gefälle an, wobei nach Süden hin ein immer kleinerer Anteil der Bevölkerung erfasst wird. Ein entgegengesetzter Trend ist beim Bruttoinlandsprodukt pro Beschäftigtem (Daten von eurostat) zu beobachten, was einen Zusammenhang nahe legt.
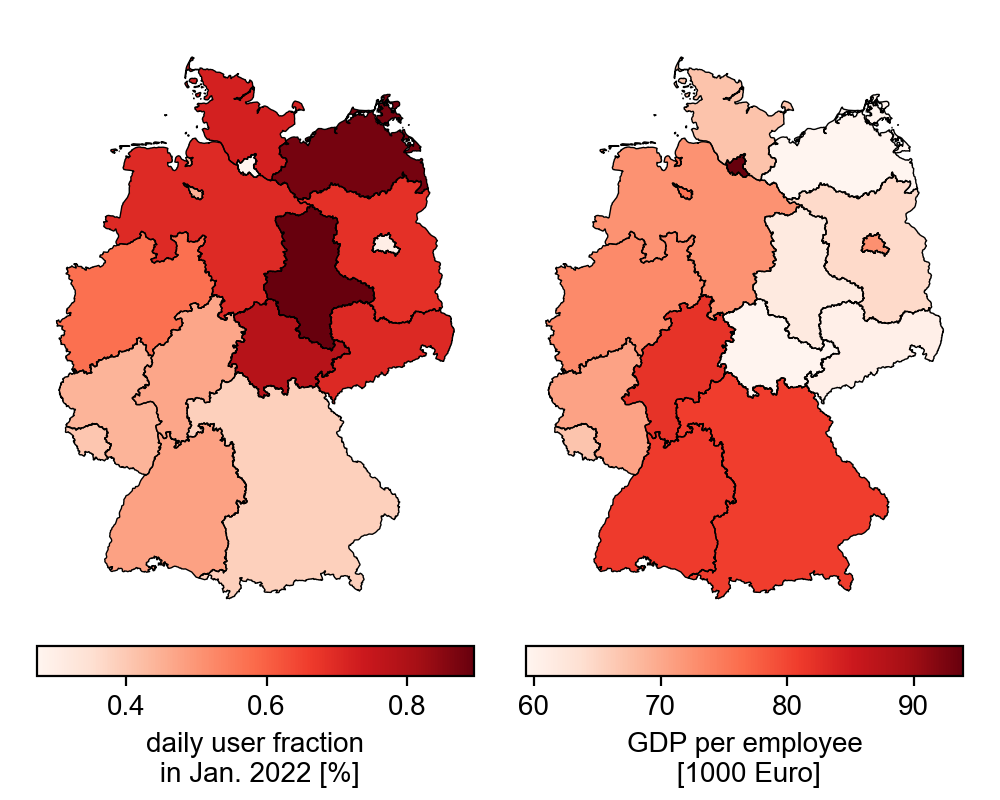
Verzerrung durch Dichte und Einkommen
In den unteren Grafiken werden die vorherigen Beobachtungen verdeutlicht. Wenn wir den Anteil der Nutzer:innen gegen das Bruttoinlandsprodukt pro Beschäftigtem auftragen, wird klar, dass ein höheres durchschnittliches Einkommen mit einem geringeren Anteil an Nutzer:innen einhergeht.
Auch die Abhängigkeit von der Bevölkerungsdichte wird offensichtlich: Bundesländer mit einer höheren Bevölkerungsdichte haben einen kleineren Anteil an Nutzer:innen. Dabei ist anzumerken, dass die x-Achse logarithmiert ist: bereits eine leicht erhöhte Bevölkerungsdichte führt zu einem starken Einbruch im Anteil der Nutzer:innen. Ändere die Skalierung in der unteren Grafik auf linear (“x-Log” -> “x-Linear”), um es zu verdeutlichen.
Da Gebiete mit einer höheren Bevölkerungsdichte mit einem höheren Einkommen einhergehen, könnten wir hier den gleichen Zusammenhang zweimal messen. Jedoch stellt sich heraus (nicht gezeigt), dass beide Maße den Anteil der Nutzer:innen unabhängig erklären. Wichtig ist, dass auch andere Maße, wie der Altersdurchschnitt, mit der Bevölkerungsdichte zusammenhängen. Also könnte es noch andere, hier nicht analysierte, Verzerrungen geben.
Wir stellen diese Unterschiede im Anteil der Nutzer:innen zwischen Bundesländern fest, aber es deutet darauf hin, dass auch innerhalb der Bundesländer (und auch bei den bundesweiten Kontaktmaßen) die Stichproben verzerrt sind: Nutzer:innen aus Regionen mit geringerer Dichte und/oder Einkommen sind wahrscheinlich in der Stichprobe des jeweiligen Bundeslandes überrepräsentiert.
Also sind in Ländern mit hoher Dichte (z.B. Berlin und Hamburg) nicht nur die Stichproben kleiner und damit mit einer höheren Unsicherheit behaftet, sondern die Stichproben sind auch weniger repräsentativ und sollten somit in den Analysen mit Vorsicht betrachtet werden. Die Verzerrung wird natürlich vor allem ein Problem, wenn Menschen mit höherem Einkommen aus dichter besiedeltem Raum ein anderes Kontaktverhalten haben als Menschen mit geringerem Einkommen vom ländlichen Raum.
Pascal Klamser
PostDoc
Pascal erforscht menschliche Mobilität, Flugnetzwerkdaten, Kontaktverhalten, kollektives Verhalten, Evolution, Phasenübergänge, Krankheiten und Meinungsdynamik.